
vllm部署生产级(低配)大模型Deepseek R1
说明
公司最近上线了bot项目,基于llm服务做数据分析,刚好有2台闲置的3090 24G*2 ,闲着也是闲着 部署个私有的LLM有何不可?最近deepseek r1模型这么火,那就先拿这个开源模型试下水吧~
说干就干,先分析下现有资源:
2*2*24G 显存,肯定做不到满血版本,而GPU机器还有其他规划还不能完全占满GPU
deepseek r1模型 32b是基于基础模型Qwen蒸馏而来,理论上Qwen国内的模型对中文的解析应该更好吧哈哈(个人理解)
后期线上用的话肯定要考虑HA单点故障出问题太被动,没有条件只能做成热备的模式,平时情况下就是负载请求
因为还要考虑其他GPU服务要占用资源,还不能把GPU占满,
所以考虑使用vllm做为模型部署服务(使用过ollama部署原生不支持多GPU负载,32B直接就把单卡24G吃满了~)
部署模型
创建虚拟环境
(base) [model@b96 ~]$ conda create -n vllm python=3.12 -y
(base) [model@b96 ~]$ conda activate vllm
(vllm) [model@b96 ~]$
安装环境和依赖
(vllm) [model@b96 ~]$ pip install torch
Installing collected packages: triton, nvidia-cusparselt-cu12, mpmath, typing-extensions, sympy, nvidia-nvtx-cu12, nvidia-nvjitlink-cu12, nvidia-nccl-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, networkx, MarkupSafe, fsspec, filelock, nvidia-cusparse-cu12, nvidia-cudnn-cu12, jinja2, nvidia-cusolver-cu12, torch
Successfully installed MarkupSafe-3.0.2 filelock-3.18.0 fsspec-2025.3.1 jinja2-3.1.6 mpmath-1.3.0 networkx-3.4.2 nvidia-cublas-cu12-12.4.5.8 nvidia-cuda-cupti-cu12-12.4.127 nvidia-cuda-nvrtc-cu12-12.4.127 nvidia-cuda-runtime-cu12-12.4.127 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.2.1.3 nvidia-curand-cu12-10.3.5.147 nvidia-cusolver-cu12-11.6.1.9 nvidia-cusparse-cu12-12.3.1.170 nvidia-cusparselt-cu12-0.6.2 nvidia-nccl-cu12-2.21.5 nvidia-nvjitlink-cu12-12.4.127 nvidia-nvtx-cu12-12.4.127 sympy-1.13.1 torch-2.6.0 triton-3.2.0 typing-extensions-4.13.0
(vllm) [model@b96 ~]$ conda install -y gxx_linux-64=9.3.0 #如果是使用centos7/anolis7等老版本GCC系统要提前安装高版本GCC要不会报下面错误
/home/model/miniconda3/envs/vllm/lib/python3.12/site-packages/torch/utils/cpp_extension.py:421: UserWarning:
!! WARNING !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Your compiler (g++ 4.8.5) may be ABI-incompatible with PyTorch!
Please use a compiler that is ABI-compatible with GCC 5.0 and above.
See https://gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html.
See https://gist.github.com/goldsborough/d466f43e8ffc948ff92de7486c5216d6
for instructions on how to install GCC 5 or higher.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! WARNING !!
warnings.warn(ABI_INCOMPATIBILITY_WARNING.format(compiler))
building 'xformers._C' extension
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/attention
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/attention/autograd
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/attention/cpu
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/sequence_parallel_fused
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/sparse24
creating build/temp.linux-x86_64-cpython-312/xformers/csrc/swiglu
g++ -pthread -B /home/model/miniconda3/envs/vllm/compiler_compat -fno-strict-overflow -Wsign-compare -DNDEBUG -O2 -Wall -fPIC -O2 -isystem /home/model/miniconda3/envs/vllm/include -fPIC -O2 -isystem /home/model/miniconda3/envs/vllm/include -fPIC -I/tmp/pip-install-t0ipftms/xformers_e4df7915e2c041d992f8a2372a32b2f0/xformers/csrc -I/home/model/miniconda3/envs/vllm/lib/python3.12/site-packages/torch/include -I/home/model/miniconda3/envs/vllm/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -I/home/model/miniconda3/envs/vllm/lib/python3.12/site-packages/torch/include/TH -I/home/model/miniconda3/envs/vllm/lib/python3.12/site-packages/torch/include/THC -I/home/model/miniconda3/envs/vllm/include/python3.12 -c xformers/csrc/attention/attention.cpp -o build/temp.linux-x86_64-cpython-312/xformers/csrc/attention/attention.o -O3 -std=c++17 -fopenmp -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -DTORCH_EXTENSION_NAME=_C -D_GLIBCXX_USE_CXX11_ABI=0
g++: error: unrecognized command line option ‘-std=c++17’
error: command '/bin/g++' failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for xformers
Running setup.py clean for xformers
Failed to build xformers
ERROR: Failed to build installable wheels for some pyproject.toml based projects (xformers)
(vllm) [model@b96 ~]$ pip install vllm
拉取huggingface模型
这里使用非deepseek官方的蒸馏模型,看着好像这个AWQ的模型要好~
https://huggingface.co/Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ
# 国内环境我们使用modelscope拉取huggingface镜像
(vllm) [model@b96 ~]$ pip install modelscope
(vllm) [model@b96 ~]$ modelscope download --model Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ --local_dir /home/model/vllm/models/
启动模型服务
(base) [model@b95 vllm]$ more run_vllm.sh
#!/bin/bash
model_path=$1
source ~/.bashrc
conda activate vllm
cd /home/model/vllm/models
vllm serve Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ --quantization awq_marlin \
--max-model-len 18432 --max-num-batched-tokens 512 --max-num-seqs 2 \
--tensor-parallel-size 2 --port 8003 --enforce-eager --gpu_memory_utilization=0.6 --enable-chunked-prefill
(base) [model@b96 vllm]$ tailf logs/Valdemardi-DeepSeek-R1-Distill-Qwen-32B-AWQ.log
INFO 04-01 13:12:08 [__init__.py:239] Automatically detected platform cuda.
INFO 04-01 13:12:09 [api_server.py:981] vLLM API server version 0.8.2
INFO 04-01 13:12:09 [api_server.py:982] args: Namespace(subparser='serve', model_tag='Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ', config='', host=None, port=8003, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, download_dir=None, load_format='auto', config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', kv_cache_dtype='auto', max_model_len=18432, guided_decoding_backend='xgrammar', logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=2, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=None, enable_prefix_caching=None, disable_sliding_window=False, use_v2_block_manager=True, num_lookahead_slots=0, seed=None, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.6, num_gpu_blocks_override=None, max_num_batched_tokens=512, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, max_num_seqs=2, max_logprobs=20, disable_log_stats=False, quantization='awq_marlin', rope_scaling=None, rope_theta=None, hf_overrides=None, enforce_eager=True, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=False, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, use_tqdm_on_load=True, multi_step_stream_outputs=True, scheduler_delay_factor=0.0, enable_chunked_prefill=True, speculative_config=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_disable_mqa_scorer=False, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, calculate_kv_scales=False, additional_config=None, enable_reasoning=False, reasoning_parser=None, disable_cascade_attn=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False, dispatch_function=<function ServeSubcommand.cmd at 0x7fe5f3e92ca0>)
INFO 04-01 13:12:16 [config.py:585] This model supports multiple tasks: {'classify', 'score', 'generate', 'reward', 'embed'}. Defaulting to 'generate'.
INFO 04-01 13:12:17 [awq_marlin.py:114] The model is convertible to awq_marlin during runtime. Using awq_marlin kernel.
INFO 04-01 13:12:17 [config.py:1519] Defaulting to use mp for distributed inference
INFO 04-01 13:12:17 [config.py:1697] Chunked prefill is enabled with max_num_batched_tokens=512.
WARNING 04-01 13:12:17 [cuda.py:95] To see benefits of async output processing, enable CUDA graph. Since, enforce-eager is enabled, async output processor cannot be used
INFO 04-01 13:12:22 [__init__.py:239] Automatically detected platform cuda.
INFO 04-01 13:12:24 [core.py:54] Initializing a V1 LLM engine (v0.8.2) with config: model='Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ', speculative_config=None, tokenizer='Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=18432, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=awq_marlin, enforce_eager=True, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=False, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[],"max_capture_size":0}
WARNING 04-01 13:12:24 [multiproc_worker_utils.py:306] Reducing Torch parallelism from 20 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
INFO 04-01 13:12:24 [shm_broadcast.py:259] vLLM message queue communication handle: Handle(local_reader_ranks=[0, 1], buffer_handle=(2, 10485760, 10, 'psm_3fa8882d'), local_subscribe_addr='ipc:///tmp/18dbe2ec-2dfa-4598-8c8a-9368bf95e167', remote_subscribe_addr=None, remote_addr_ipv6=False)
INFO 04-01 13:12:28 [__init__.py:239] Automatically detected platform cuda.
WARNING 04-01 13:12:31 [utils.py:2321] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7f9343e04d40>
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:31 [shm_broadcast.py:259] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_f3239d2d'), local_subscribe_addr='ipc:///tmp/0e8a1de9-da64-4a43-9189-d1e2340b172b', remote_subscribe_addr=None, remote_addr_ipv6=False)
INFO 04-01 13:12:34 [__init__.py:239] Automatically detected platform cuda.
WARNING 04-01 13:12:37 [utils.py:2321] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7f5bf269a600>
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:37 [shm_broadcast.py:259] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_2cf0aeda'), local_subscribe_addr='ipc:///tmp/fc78e3a3-967a-44d4-b372-db2895376603', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [utils.py:931] Found nccl from library libnccl.so.2
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [utils.py:931] Found nccl from library libnccl.so.2
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [custom_all_reduce_utils.py:244] reading GPU P2P access cache from /home/model/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [custom_all_reduce_utils.py:244] reading GPU P2P access cache from /home/model/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
(VllmWorker rank=1 pid=33453) WARNING 04-01 13:12:38 [custom_all_reduce.py:146] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorker rank=0 pid=33437) WARNING 04-01 13:12:38 [custom_all_reduce.py:146] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [shm_broadcast.py:259] vLLM message queue communication handle: Handle(local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_2bbd63db'), local_subscribe_addr='ipc:///tmp/e8940514-c220-4496-8a40-8745f189fbc1', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [parallel_state.py:954] rank 1 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 1
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [parallel_state.py:954] rank 0 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 0
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [cuda.py:220] Using Flash Attention backend on V1 engine.
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [cuda.py:220] Using Flash Attention backend on V1 engine.
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:38 [gpu_model_runner.py:1174] Starting to load model Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ...
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:38 [gpu_model_runner.py:1174] Starting to load model Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ...
(VllmWorker rank=1 pid=33453) WARNING 04-01 13:12:38 [topk_topp_sampler.py:63] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(VllmWorker rank=0 pid=33437) WARNING 04-01 13:12:38 [topk_topp_sampler.py:63] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:01<00:03, 1.22s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [00:02<00:02, 1.42s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [00:04<00:01, 1.46s/it]
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:44 [loader.py:447] Loading weights took 5.45 seconds
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:05<00:00, 1.34s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [00:05<00:00, 1.36s/it]
(VllmWorker rank=0 pid=33437)
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:44 [loader.py:447] Loading weights took 5.52 seconds
(VllmWorker rank=1 pid=33453) INFO 04-01 13:12:45 [gpu_model_runner.py:1186] Model loading took 9.1202 GB and 6.948376 seconds
(VllmWorker rank=0 pid=33437) INFO 04-01 13:12:45 [gpu_model_runner.py:1186] Model loading took 9.1202 GB and 7.037842 seconds
INFO 04-01 13:12:49 [kv_cache_utils.py:566] GPU KV cache size: 36,368 tokens
INFO 04-01 13:12:49 [kv_cache_utils.py:569] Maximum concurrency for 18,432 tokens per request: 1.97x
INFO 04-01 13:12:49 [kv_cache_utils.py:566] GPU KV cache size: 36,368 tokens
INFO 04-01 13:12:49 [kv_cache_utils.py:569] Maximum concurrency for 18,432 tokens per request: 1.97x
INFO 04-01 13:12:50 [core.py:151] init engine (profile, create kv cache, warmup model) took 4.23 seconds
INFO 04-01 13:12:50 [api_server.py:1028] Starting vLLM API server on http://0.0.0.0:8003
INFO 04-01 13:12:50 [launcher.py:26] Available routes are:
INFO 04-01 13:12:50 [launcher.py:34] Route: /openapi.json, Methods: HEAD, GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /docs, Methods: HEAD, GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /docs/oauth2-redirect, Methods: HEAD, GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /redoc, Methods: HEAD, GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /health, Methods: GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /load, Methods: GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /ping, Methods: POST, GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /tokenize, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /detokenize, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/models, Methods: GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /version, Methods: GET
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/chat/completions, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/completions, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/embeddings, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /pooling, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /score, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/score, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/audio/transcriptions, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /rerank, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v1/rerank, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /v2/rerank, Methods: POST
INFO 04-01 13:12:50 [launcher.py:34] Route: /invocations, Methods: POST
INFO: Started server process [33291]
INFO: Waiting for application startup.
INFO: Application startup complete.模型HA
通过nginx+keepalived负载到相同配置的2个 vllm上,这里不再赘述。
还有不要忘了在nginx上做IP限制,因为我们这个是没有认证的。
模型使用和测试
个人习惯用cherry studio做为客户端
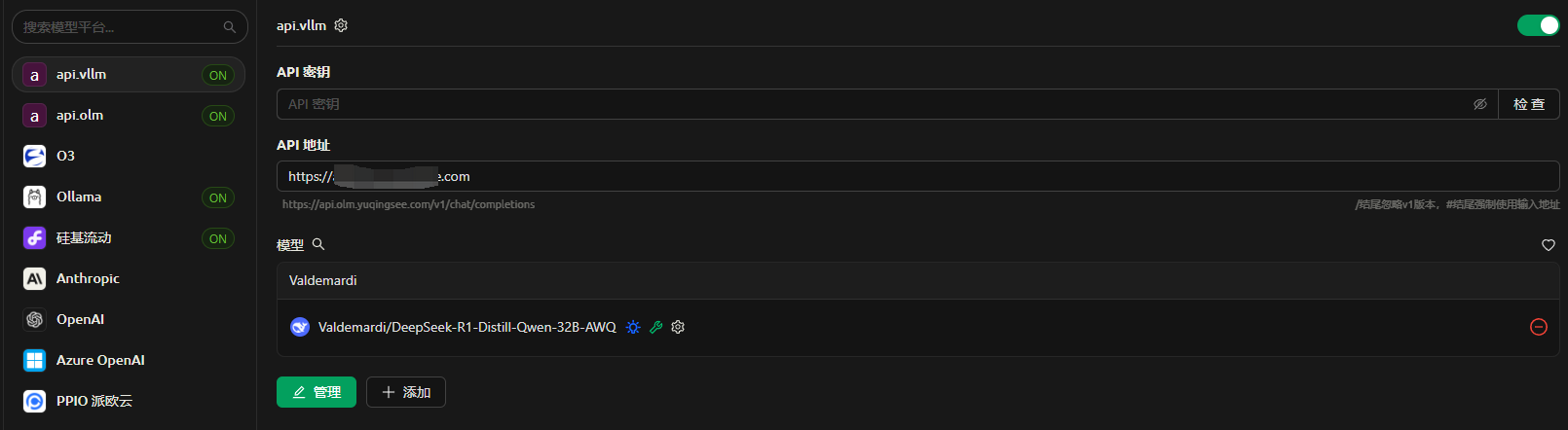
速度测试3090 24G
实际测试,1台 1并发请求速度可达23+ tokens/s
我们的环境2并发2节点,理论上可达 92+tokens/s
INFO 04-01 13:33:30 [async_llm.py:221] Added request chatcmpl-0204e3a489c8480aa2d1cc9674ba78c0.
INFO 04-01 13:33:32 [loggers.py:80] Avg prompt throughput: 292.4 tokens/s, Avg generation throughput: 0.1 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 8.2%, Prefix cache hit rate: 0.0%
INFO 04-01 13:33:42 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 23.4 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 8.9%, Prefix cache hit rate: 0.0%
INFO 04-01 13:33:52 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 23.5 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 9.5%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:02 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 23.5 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 10.0%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:12 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 23.6 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 10.6%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:22 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 23.5 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 11.3%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:32 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 12.3 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:42 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
INFO 04-01 13:34:52 [loggers.py:80] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%关于结果准确性
不太懂,但结果和思考过程上是比ollama+官方32b 要好不少,同样的prompt官方的结果都会有格式会乱,思考过程也有问题~
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
运维有道!
喜欢就支持一下吧
大模型Deepseek R1&pics=https://s2.loli.net/2024/03/07/3kIpCwEKNbSxoAc.jpg&summary=){kind=link}
大模型Deepseek R1&pics=https://s2.loli.net/2024/03/07/3kIpCwEKNbSxoAc.jpg&desc=){kind=link}